ScyllaDB basics
Written on October 26, 2024
Notes on ScyllaDB
ScyllaDB is a NoSQL, peer-to-peer distributed database built to manage big data while eliminating single points of failure. It ensures high availability even in the event of hardware or network issues.
The database design is based on several key principles:
- High Scalability: ScyllaDB can scale both horizontally (by adding more nodes) and vertically (by efficiently utilizing modern multi-core CPUs, multi-CPU nodes, and high-capacity storage).
- High Availability: The system maintains low latency and remains operational even if one or more nodes fail or there is a network disruption.
- High Performance: ScyllaDB operates close to the hardware level, ensuring low, consistent latency and high throughput.
- Low Maintenance: It includes user-friendly features such as automated configurations and self-tuning capabilities, reducing the need for manual intervention.
For users familiar with Apache Cassandra®, many ScyllaDB commands and features will feel intuitive. This is because ScyllaDB was designed to be fully compatible with Cassandra at the API level.
My setup script
# Setup scylla db
# Echo get the number of nodes to run
echo "Enter the number of nodes to run"
read num_nodes
# Setup docker network scylla_net if it does not exist
docker network inspect scylla_net > /dev/null 2>&1
if [ $? -eq 1 ]; then
docker network create scylla_net
fi
# Run scylla db node1
docker run --name node1 --network scylla_net -d scylladb/scylla:6.1.1 --overprovisioned 1 --smp 1 --reactor-backend=epoll
# Seed node with ip of node1
seed_ip=$(docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' node1)
# Echo seed ip
echo "Seed node ip: $seed_ip"
# Run the rest of the nodes
if [ $num_nodes -gt 1 ]; then
for i in $(seq 2 $num_nodes); do
docker run --name node$i --network scylla_net -d scylladb/scylla:6.1.1 --seeds="$seed_ip" --overprovisioned 1 --smp 1 --reactor-backend=epoll
done
fiNode
A node is the fundamental building block of a ScyllaDB database, consisting of the ScyllaDB server software running on a physical or virtual server.
Each node holds a portion of the overall database cluster's data and is divided into multiple independent shards.
In ScyllaDB, all nodes are equal, with no master or slave roles. Every node is capable of handling requests, and they collaborate to ensure continuous service, even if one node becomes unavailable due to a failure.
Keyspace and Table
A Keyspace is a collection of tables with settings that determine how data is replicated across nodes (Replication Strategy). It includes several options that apply to all the tables within it. Typically, it's advised to use one Keyspace per application, so a cluster might have only a single Keyspace.
A Table represents how ScyllaDB organizes and stores data, functioning as a collection of rows and columns.
Cluster – Node Ring
A Cluster in ScyllaDB is a collection of nodes used to store and manage data, with the nodes arranged in a logical ring structure. Typically, a cluster consists of at least three nodes, and data is automatically replicated across these nodes based on the defined Replication Factor.
This ring-like architecture is based on a hash ring, which guides how data is distributed across the nodes within the cluster.
Clusters can scale dynamically, either by adding nodes to increase storage and processing capabilities or by removing nodes through planned decommissioning or in response to failures. When the cluster's topology changes, ScyllaDB automatically reconfigures itself to rebalance the data.
While a ScyllaDB cluster requires a minimum of three nodes, it can scale to include hundreds. Communication between nodes within the cluster is peer-to-peer, eliminating any single point of failure. For external communication, such as read or write operations, a ScyllaDB client connects to a single node called the coordinator. This coordinator is selected for each client request, preventing any one node from becoming a bottleneck. Further details on this process are provided later in the lesson.
A Partition Key consists of one or more columns that determine how data is distributed across the nodes. It decides where a specific row will be stored. Typically, data is replicated across multiple nodes, ensuring that even if one node fails, the data remains accessible, providing reliability and fault tolerance.
For example, if the Partition Key is the ID column, a consistent hash function will determine which nodes store the data.
ScyllaDB transparently partitions and distributes data throughout the cluster. Data replication ensures availability, and the cluster is visualized as a ring, where each node manages a range of tokens. Each data value is associated with a token using a partition key:
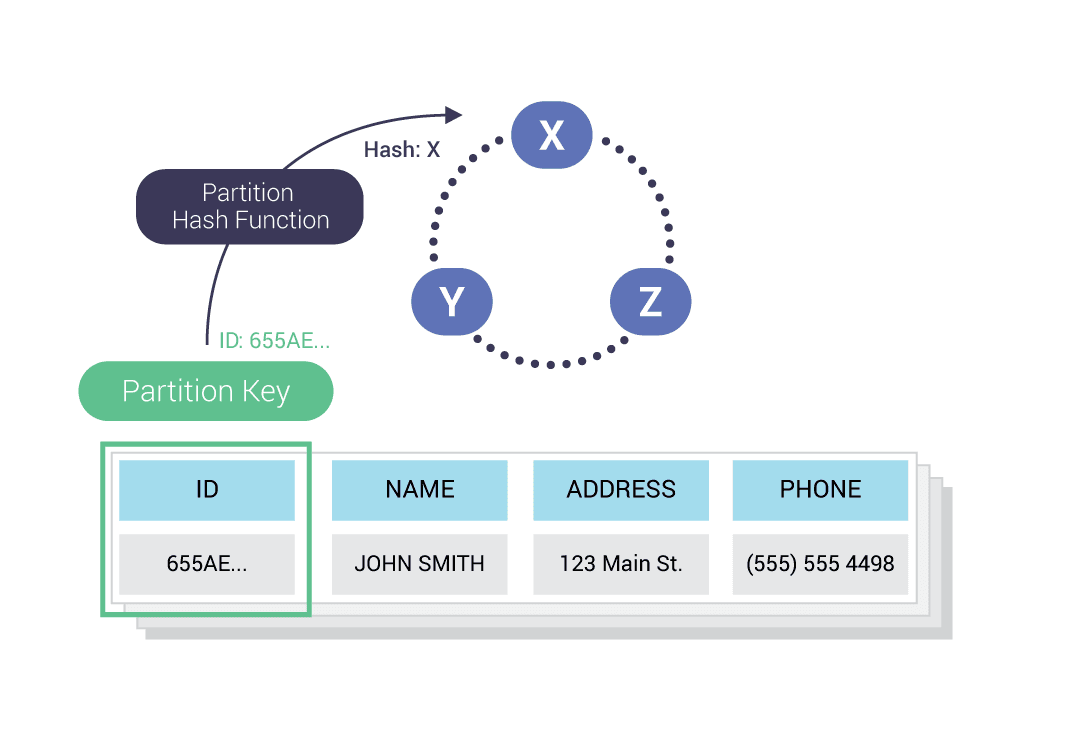
Data Replication
To eliminate any single point of failure, ScyllaDB uses data replication, which involves storing copies of data across multiple nodes. This ensures that even if one node fails, the data remains accessible, providing reliability and fault tolerance. The number of copies, or Replication Factor (RF), determines how many times the data is duplicated.
For instance, a Replication Factor of 3 (RF=3) means that three copies of the data are maintained at all times. Users set the RF for a specific keyspace, and based on this setting, the coordinator distributes the data to other nodes, known as replicas, to ensure redundancy and fault tolerance.
Shard
Each ScyllaDB node is divided into several independent shards, with each shard managing a portion of the node's data. ScyllaDB allocates one shard per core (technically, one per hyperthread, meaning a physical core may support multiple virtual cores). Each shard follows a shared-nothing architecture, meaning it has dedicated RAM and storage, manages its own CPU and I/O scheduling, performs compactions (explained further later), and maintains its own multi-queue network connection. Shards operate as single threads and communicate asynchronously with each other without the need for locking.
From an external perspective, nodes are treated as unified entities, with operations executed at the node level.
Datacenter
A datacenter is a physical facility that houses servers, storage systems, and networking equipment. Cloud providers operate multiple datacenters across various countries worldwide.
ScyllaDB is designed to be fault-tolerant at the software level and is also aware of the datacenter's topology. For instance, you might want to place replica nodes on different racks within a datacenter to reduce the risk of disruptions caused by rack-specific network or power failures. ScyllaDB manages this using a mechanism called snitches.
A Rack is a metal framework that holds hardware components such as servers, hard drives, and networking devices. ScyllaDB recognizes logical racks to add an extra layer of fault tolerance, ensuring that if one rack (or even an entire datacenter) fails, data remains accessible.
ScyllaDB also supports multi-datacenter replication, enabling data sharing and distribution across two or more datacenters. The replication strategy allows you to specify the number of datacenters for replication and set distinct replication factors for each one.
Datacenters in ScyllaDB are configured in a peer-to-peer manner, meaning there is no central authority, nor are there "primary/replica" hierarchical relationships between clusters.
This setup enables data replication across clusters to handle localized traffic with minimal latency and high throughput, and to ensure resilience in case of a complete datacenter outage.
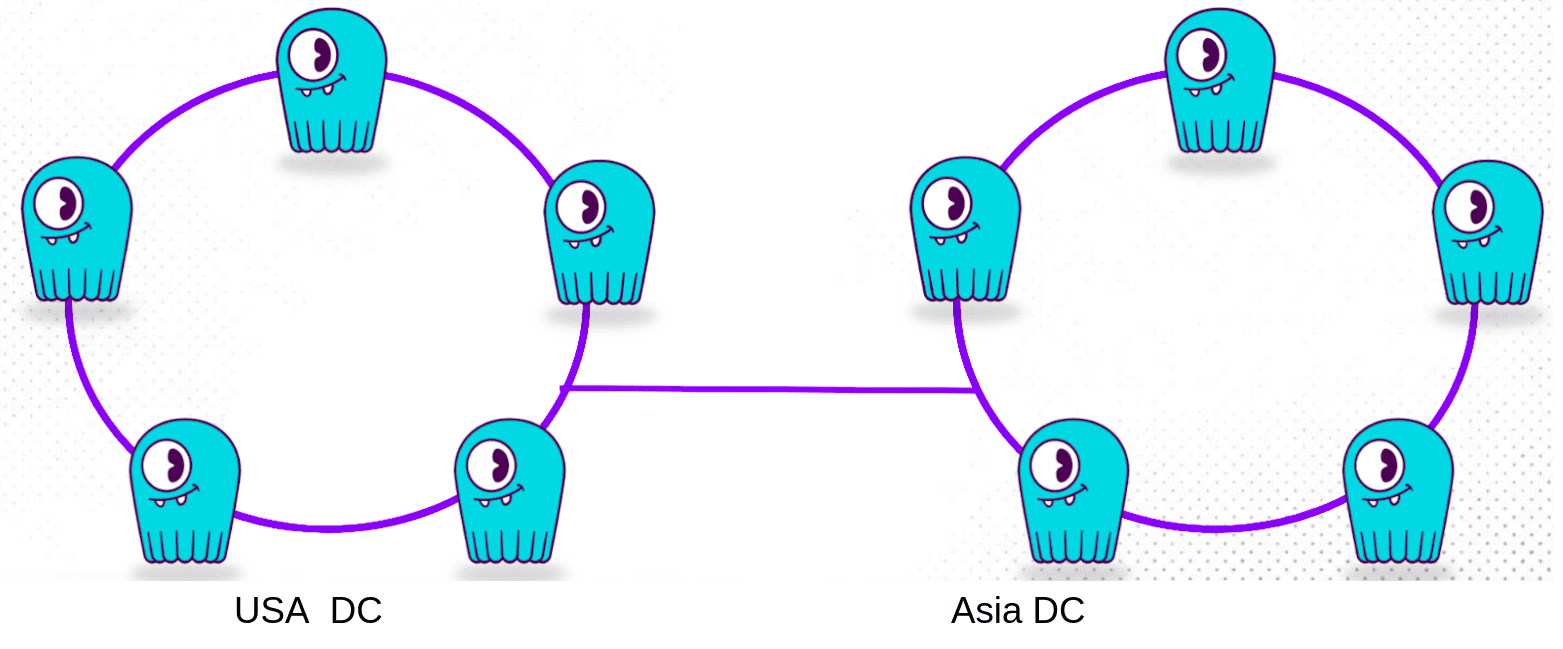
Replication Strategy
The Replication Strategy defines how replicas are distributed across nodes. ScyllaDB offers two replication strategies:
- SimpleStrategy: The first replica is placed on the node determined by the partitioner, which is a hash function used to map data to specific nodes in the cluster. Subsequent replicas are positioned clockwise around the node ring. This strategy is not recommended for production environments.
- NetworkTopologyStrategy: Replicas are placed clockwise around the ring until a node on a different rack is reached. This strategy is ideal for clusters spread across multiple datacenters, as it allows you to specify the number of replicas for each datacenter.
For example, if there are two datacenters, DC1 with a replication factor of 3 and DC2 with a replication factor of 2, the overall replication factor for the keyspace would be 5. Below, we'll demonstrate how to create such a keyspace.
Token Ranges
In a ScyllaDB ring, each node is responsible for a specific token range. The hash function generates a token based on the partition key, which determines where the data is stored within the cluster.
Without virtual nodes (Vnodes), each node would manage only a single token range. However, with Vnodes, each physical node can handle multiple, non-contiguous token ranges, effectively allowing it to act as many virtual nodes. By default, each physical node is configured to host 256 virtual nodes.
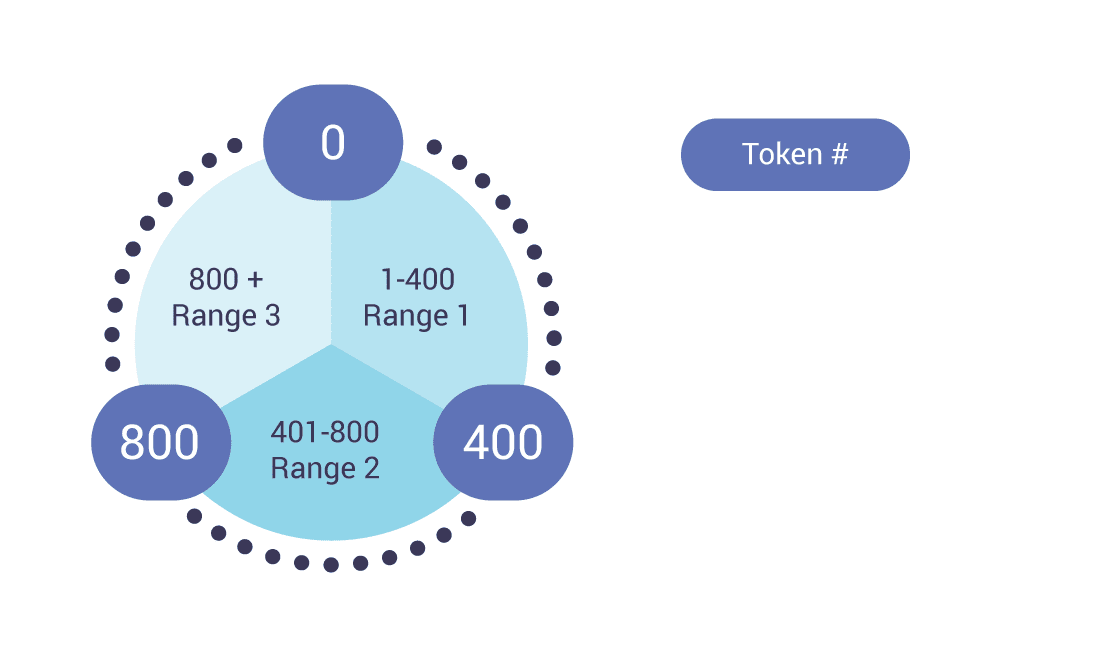
Consistency Level (CL)
The number of nodes that must confirm a read or write operation before it is considered successful is defined by the consistency level.
To ensure data is correctly written or read, a sufficient number of nodes need to agree on its current state. Although consistency levels can be set globally for all operations (on the client side), ScyllaDB allows each read or write operation to have its own specific consistency level, a feature known as tunable consistency.
Here are some common consistency levels:
- CL of 1: Wait for a response from a single replica node.
- CL of ALL: Wait for a response from all replica nodes.
- CL LOCAL_QUORUM: Wait for responses from a majority of replica nodes in the local datacenter, calculated as
floor((#dc_replicas / 2) + 1). For example, if a datacenter has 3 replica nodes, the operation will wait for a response from 2 nodes. - CL EACH_QUORUM: In multi-datacenter setups, each datacenter must reach a LOCAL_QUORUM. This level is not supported for read operations.
- CL ALL: Requires responses from all replica nodes, providing the highest level of consistency but at the cost of reduced availability.
Since data may be updated on the coordinator node but not yet fully replicated across all nodes, ScyllaDB implements eventual consistency. With this model, all replicas will eventually synchronize to the same data state, even as operations continue to update the database.
Cluster Level Read/Write Interaction
So what happens when data is read or written at the cluster level? Note that what happens at the node level will be explained in another lesson.
Since each node is equal in ScyllaDB, any node can receive a read/write request. These are the main steps in the process:
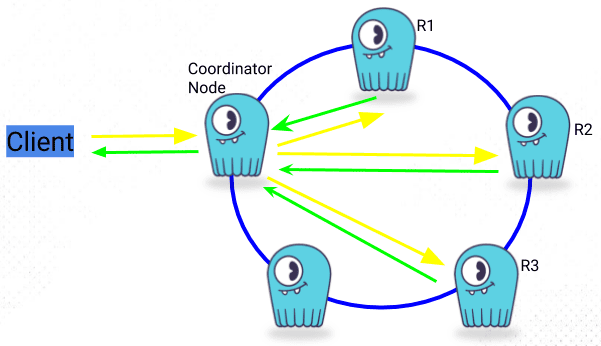 ]
]
- A client connects to a ScyllaDB node using the CQL shell and performs a CQL request
- The node the client is connected to is now designated as the Coordinator Node. The Coordinator Node, based on hashing the data, using the partition key and on the Replication Strategy, sends the request to the applicable nodes. Internode messages are sent through a messaging queue asynchronously.
- The Consistency Level determines the number of nodes the coordinator needs to hear back from for the request to be successful.
- The client is notified if the request is successful.
Gossip
ScyllaDB, similar to Apache Cassandra, employs a decentralized internode communication protocol known as Gossip. This protocol allows nodes to exchange information without relying on a single point of failure. Gossip is used for tasks such as peer node discovery and the distribution of metadata across the cluster. Communication happens periodically, with each node interacting with three other nodes. Over a short period (usually a few seconds), this information spreads throughout the entire cluster.
Snitch
The Snitch in ScyllaDB determines which racks and datacenters should be used for reading and writing data. ScyllaDB offers the following types of snitches:
- SimpleSnitch: The default option, recommended only for single datacenter clusters.
- RackInferringSnitch: Assigns nodes to datacenters and racks based on their broadcast IP addresses.
- GossipingPropertyFileSnitch: Explicitly defines the rack and datacenter for each node. Preferred over SimpleSnitch for better configuration.
- Ec2Snitch: Automatically detects the cluster topology using the AWS API, suitable for single-region deployments on AWS where the region acts as a datacenter.
- Ec2MultiRegionSnitch: Similar to Ec2Snitch but designed for clusters spread across multiple AWS regions.
- GoogleCloudSnitch: Designed for ScyllaDB deployments on Google Cloud Engine (GCE). Treats regions as datacenters and availability zones as racks within those datacenters.
My ScyllaDB docker-compose setup
services:
node1:
image: scylladb/scylla
container_name: node1
command: --overprovisioned 1 --smp 1 --reactor-backend=epoll
volumes:
- ./data/node1:/var/lib/scylla
node2:
image: scylladb/scylla
container_name: node2
command: --seeds=node1 --overprovisioned 1 --smp 1 --reactor-backend=epoll
volumes:
- ./data/node2:/var/lib/scylla
node3:
image: scylladb/scylla
container_name: node3
command: --seeds=node1 --overprovisioned 1 --smp 1 --reactor-backend=epoll
volumes:
- ./data/node3:/var/lib/scylla