Async in JavaScript
Written on December 3, 2021
Javascript asynchronous code execution flow
Javascript is a wonderful language and really provides many tools for code execution. One of the strengths of js is how it handles Asynchronous (async) code.
Rather than blocking the main execution thread, async code gets pushed to the event queue that fires after all other code executes. It can, however, be difficult for beginners to follow async code. This article aims to clarify all of that.
Understanding Async Code
So the most basic example of asynchronous code in js are setTimout and setInterval.
setTimout executes a function after a certain amount of time passes. It accepts a callback function and time(in milliseconds) as the second argument.
console.log('a')
setTimeout(function () {
console.log('c')
}, 100)
setTimeout(function () {
console.log('d')
}, 100)
setTimeout(function () {
console.log('e')
}, 100)
console.log('b')
/* The output will be
a
b
c
d
e
*/Here we can see that the output matches our expectation.
The execution of code happened as following,
- on first line it blocking-ly executed
console.log('a') - then it saw an asynchronous function which it added to the event queue.
- understand that it hasn't started executing the code yet, that will happen later.
- similarly it added second and third
setTimeoutto event queue. - eventually it reached
console.log('b')which it executed blocking-ly. - and after all the code has been executed in the block. then only js engine starts executing the async code from event queue.
The event loop is a queue of callback functions. When an async function executes, the callback function is pushed into the queue. The javascript engine doesn't start processing the event loop until the code after an async function has executed. This allows us to see that our js code is not multi-threaded, even though it appears so.
The Event loop is a FIFO queue, meaning the callback function will execute in the order they were added onto the queue. And using node allows us to use this asynchronous behavior on the backend as well.
Various ways to use async code execution
- Callbacks
- Named function [passing functions as variables]
- Promises [dependent on callbacks]
- Events
Callbacks
This is the main method any async code is executed. Async programming lends itself to what's commonly referred to as "callback hell". Because virtually all async functions in JavaScript use callbacks, performing multiple sequential async functions result in many nested callbacks--resulting in hard to read code.
const fs = require('fs')
fs.exists('index.js', function () {
fs.readFile('index.js', 'utf8', function (err, contents) {
contents = someFunction(contents) // do something with contents
fs.writeFile('index.js', 'utf8', function () {
console.log('whew! Done finally...')
})
})
})
console.log('executing...')Nested callbacks can get really nasty, but there are several solutions to this style of coding.
Named functions
An easy solution that cleans nested callbacks is simply avoiding nesting more than two levels. Instead of passing anonymous functions to the callback arguments, pass a named function, which is a feature that javascript provides us.
var fromLatLng, toLatLng
// And lastly this function will execute
var routeDone = function (e) {
console.log("ANNNND FINALLY here's the directions...")
// do something with e
}
// Secondly this function will execute
var toAddressDone = function (results, status) {
if (status == 'OK') {
toLatLng = results[0].geometry.location
map.getRoutes({
origin: [fromLatLng.lat(), fromLatLng.lng()],
destination: [toLatLng.lat(), toLatLng.lng()],
travelMode: 'driving',
unitSystem: 'imperial',
callback: routeDone,
})
}
}
// First this function will execute
var fromAddressDone = function (results, status) {
if (status == 'OK') {
fromLatLng = results[0].geometry.location
GMaps.geocode({
address: toAddress,
callback: toAddressDone,
})
}
}
// Initializing function
GMaps.geocode({
address: fromAddress, // address object is defined globally
callback: fromAddressDone,
})Promises
While using named functions is a neat concept that is widely used, but keeping track of named function variables can get quite daunting, quite fast.
And there's no guarantee that those variables can't be overridden by other parts of our program.
For this reason and where we are sure about the flow of the data. We can use promises, which allows us to chain functions to achieve a desired state in our application.
Let's look at how we can initialize a promise
let promise = new Promise(function (resolve, reject) {
// the executor function is executed
// automatically when the promise is constructed
// after 1 second signal that the job is
// done with the result "done"
setTimeout(() => resolve('done'), 1000)
})Consumers
Now the part where we chain the consumer functions
A Promise object serves as a link between the executor (the “producing code”) and the consuming functions, which will receive the result or error. Consuming functions can be registered (subscribed) using methods .then, .catch and .finally.
then
The most important, fundamental one is .then.
promise.then(
function (result) {
/* handle a successful result */
},
function (error) {
/* handle an error */
}
)The first argument of .then is a function that runs when the promise is resolved, and receives the result.
The second argument of .then is a function that runs when the promise is rejected, and receives the error.
catch
If we’re interested only in errors, then we can use null as the first argument: .then(null, errorHandlingFunction). Or we can use .catch(errorHandlingFunction), which is exactly the same:
let promise = new Promise((resolve, reject) => {
setTimeout(() => reject(new Error('Whoops!')), 1000)
})
// .catch(f) is the same as promise.then(null, f)
promise.catch(alert) // shows "Error: Whoops!" after 1 secondThe call .catch(f) is a complete analog of .then(null, f), it’s just a shorthand.
finally
Just like there’s a finally clause in a regular try {...} catch {...}, there’s finally in promises.
The call .finally(f) is similar to .then(f, f) in the sense that f always runs when the promise is settled: be it resolve or reject.
finally is a good handler for performing cleanup, e.g. stopping our loading indicators, as they are not needed anymore, no matter what the outcome is.
Like this:
new Promise((resolve, reject) => {
/* do something that takes time, and then call resolve/reject */
})
// runs when the promise is settled
// doesn't matter successfully or not
.finally(() => stop loading indicator)
// so the loading indicator is always
// stopped before we process the result/error
.then(result => show result, err => show error)That said, finally(f) isn’t exactly an alias of then(f,f) though. There are few subtle differences:
A
finallyhandler has no arguments. Infinallywe don’t know whether the promise is successful or not. That’s all right, as our task is usually to perform “general” finalizing procedures.A
finallyhandler passes through results and errors to the next handler.For instance, here the result is passed through
finallytothen:
new Promise((resolve, reject) => {
setTimeout(() => resolve('result'), 2000)
})
.finally(() => alert('Promise ready'))
.then((result) => alert(result)) // <-- .then handles the resultAnd here there’s an error in the promise, passed through finally to catch:
new Promise((resolve, reject) => {
throw new Error('error')
})
.finally(() => alert('Promise ready'))
.catch((err) => alert(err)) // <-- .catch handles the error objectThat’s very convenient, because finally is not meant to process a promise result. So it passes it through.
Events
Events are another solution to communicate when async callbacks finish executing. An object can become an emitter and publish events that other objects can listen for. This type of eventing is called the observer pattern.
The Event Loop is a queue of callback functions.
Browser JavaScript execution flow, as well as in Node.js, is based on an event loop.
Understanding how event loop works is important for optimizations, and sometimes for the right architecture.
In this chapter we first cover theoretical details about how things work, and then see practical applications of that knowledge.
Event Loop
The event loop concept is very simple. There’s an endless loop, where the JavaScript engine waits for tasks, executes them and then sleeps, waiting for more tasks.
The general algorithm of the engine:
- While there are tasks:
- execute them, starting with the oldest task.
- Sleep until a task appears, then go to 1.
That’s a formalization for what we see when browsing a page. The JavaScript engine does nothing most of the time, it only runs if a script/handler/event activates.
Examples of tasks:
- When an external script
<script src="...">loads, the task is to execute it. - When a user moves their mouse, the task is to dispatch
mousemoveevent and execute handlers. - When the time is due for a scheduled
setTimeout, the task is to run its callback. - …and so on.
Tasks are set – the engine handles them – then waits for more tasks (while sleeping and consuming close to zero CPU).
It may happen that a task comes while the engine is busy, then it’s enqueued.
The tasks form a queue, so-called “macrotask queue” (v8 term):
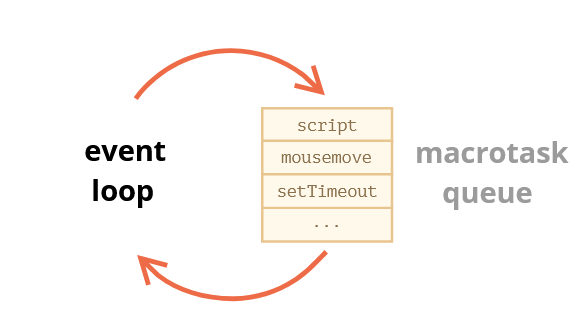
For instance, while the engine is busy executing a script, a user may move their mouse causing mousemove, and setTimeout may be due and so on, these tasks form a queue, as illustrated on the picture above.
Tasks from the queue are processed on “first come – first served” basis. When the engine browser is done with the script, it handles mousemove event, then setTimeout handler, and so on.
So far, quite simple, right?
Two more details:
- Rendering never happens while the engine executes a task. It doesn't matter if the task takes a long time. Changes to the DOM are painted only after the task is complete.
- If a task takes too long, the browser can’t do other tasks, such as processing user events. So after a time, it raises an alert like “Page Unresponsive”, suggesting killing the task with the whole page. That happens when there are a lot of complex calculations or a programming error leading to an infinite loop.
Microtasks
Along with macrotasks, described in this chapter, there are microtasks, mentioned in the chapter Microtasks.
Microtasks come solely from our code. They are usually created by promises: an execution of .then/catch/finally handler becomes a microtask. Microtasks are used “under the cover” of await as well, as it’s another form of promise handling.
There’s also a special function queueMicrotask(func) that queues func for execution in the microtask queue.
Immediately after every macrotask, the engine executes all tasks from microtask queue, prior to running any other macrotasks or rendering or anything else.
For instance, take a look:
setTimeout(() => alert('timeout'))
Promise.resolve().then(() => alert('promise'))
alert('code')What’s going to be the order here?
codeshows first, because it’s a regular synchronous call.promiseshows second, because.thenpasses through the microtask queue, and runs after the current code.timeoutshows last, because it’s a macrotask.
The richer event loop picture looks like this (order is from top to bottom, that is: the script first, then microtasks, rendering and so on):
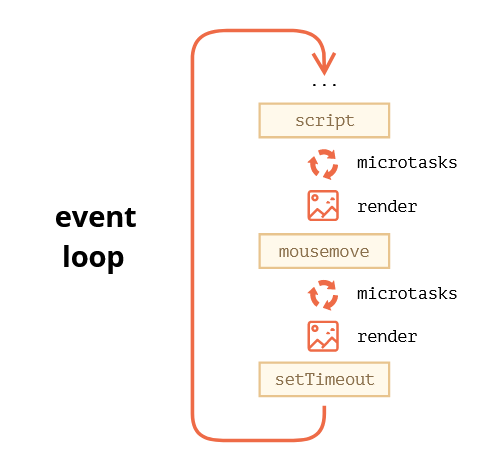
All microtasks are completed before any other event handling or rendering or any other macrotask takes place.
That’s important, as it guarantees that the application environment is basically the same (no mouse coordinate changes, no new network data, etc) between microtasks.
If we’d like to execute a function asynchronously (after the current code), but before changes are rendered or new events handled, we can schedule it with queueMicrotask.
Summary
A more detailed event loop algorithm (though still simplified compared to the specification):
- Dequeue and run the oldest task from the macrotask queue (e.g. “script”).
- Execute all microtasks:
- While the microtask queue is not empty:
- Dequeue and run the oldest microtask.
- While the microtask queue is not empty:
- Render changes if any.
- If the macrotask queue is empty, wait till a macrotask appears.
- Go to step 1.
To schedule a new macrotask:
- Use zero delayed
setTimeout(f).
That may be used to split a big calculation-heavy task into pieces, for the browser to be able to react to user events and show progress between them.
Also, used in event handlers to schedule an action after the event is fully handled (bubbling done).
To schedule a new microtask
- Use
queueMicrotask(f). - Also promise handlers go through the microtask queue.
There’s no UI or network event handling between microtasks: they run immediately one after another.
So one may want to queueMicrotask to execute a function asynchronously, but within the environment state.
In most Javascript engines, including browsers and Node.js, the concept of microtasks is closely tied with the “event loop” and “macrotasks”. As these have no direct relation to promises, they are covered in another part of the tutorial, in the article Event loop: microtasks and macrotasks.